The smallest unit of data that can be manipulated in SQL is called a value. How values are interpreted depends on the data type of their source. The sources of values are:
The DB2® UDB relational database products support both built-in data types and user-defined data types. This section describes the built-in data types. For a description of distinct types, see User-defined types.
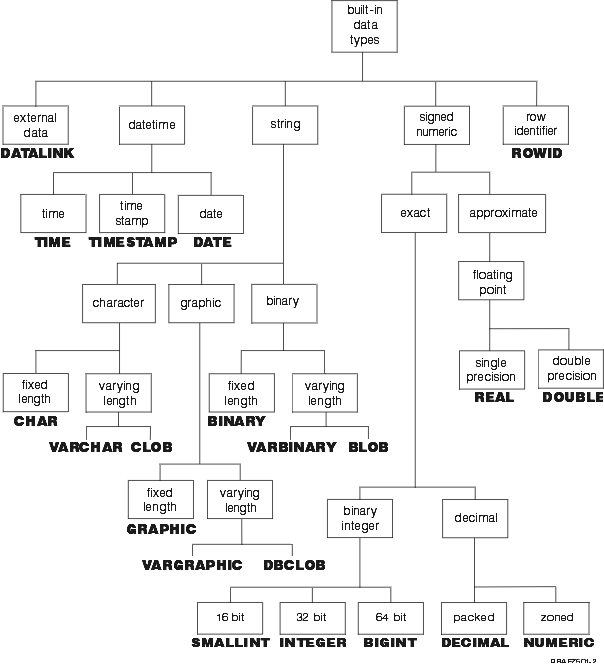
The following figure illustrates the various built-in data types supported by the DB2 UDB for iSeries program.
For more details on data types, see the following topics:
For information about specifying the data types of columns, see CREATE TABLE.
All data types include the null value. Distinct from all non-null values, the null value is a special value that denotes the absence of a (non-null) value. Except for grouping operations, a null value is also distinct from another null value. Although all data types include the null value, some sources of values cannot provide the null value. For example, constants, columns that are defined as NOT NULL, and special registers cannot contain null values; the COUNT and COUNT_BIG functions cannot return a null value; and ROWID columns cannot store a null value although a null value can be returned for a ROWID column as the result of a query.
The numeric data types are binary integer, floating-point, and decimal. Binary integer includes small integer, large integer, and big integer. Floating-point includes single precision and double precision. Binary numbers are exact representations of integers. Decimal numbers are exact representations of real numbers. Binary and decimal numbers are considered exact numeric types. Floating-point numbers are approximations of real numbers and are considered approximate numeric types.
All numbers have a sign, a precision, and a scale. If a column value is zero, the sign is positive. The precision is the total number of binary or decimal digits excluding the sign. The scale is the total number of binary or decimal digits to the right of the decimal point. If there is no decimal point, the scale is zero.
A small integer is a binary number composed of 2 bytes with a precision of 5 digits. The range of small integers is -32768 to +32767.
For small integers, decimal precision and scale are supported by COBOL, RPG, and iSeries system files. For information concerning the precision and scale of binary integers, see the DDS Reference book.
A large integer is a binary number composed of 4 bytes with a precision of 10 digits. The range of large integers is -2147483648 to +2147483647.
For large integers, decimal precision and scale are supported by COBOL, RPG, and iSeries system files. For information concerning the precision and scale of binary integers, see the DDS Reference book.
A big integer is a binary number composed of 8 bytes with a precision of 19 digits. The range of big integers is -9223372036854775808 to +9223372036854775807.
A single-precision floating-point number is a 32-bit approximate representation of a real number. The range of magnitude is approximately 1.17549436 × 10-38 to 3.40282356 × 1038.
A double-precision floating-point number is a IEEE 64-bit approximate representation of a real number. The range of magnitude is approximately 2.2250738585072014 × 10-308 to 1.7976931348623158 × 10308.
See Table 77 for more information.
A decimal value is a packed decimal or zoned decimal number with an implicit decimal point. The position of the decimal point is determined by the precision and the scale of the number. The scale, which is the number of digits in the fractional part of the number, cannot be negative or greater than the precision. The maximum precision is 63 digits.
All values of a decimal column have the same precision and scale. The range of a decimal variable or the numbers in a decimal column is -n to +n, where the absolute value of n is the largest number that can be represented with the applicable precision and scale.
The maximum range is negative 1063+1 to 1063 minus 1.
Small and large binary integer variables can be used in all host languages. Big integer variables can only be used in C, C++, ILE COBOL, and ILE RPG. Floating-point variables can be used in all host languages except RPG/400® and COBOL/400®. Decimal variables can be used in all supported host languages.
When a decimal or floating-point number is cast to a string (for example, using a CAST specification) the implicit decimal point is replaced by the default decimal separator character in effect when the statement was prepared. When a string is cast to a decimal or floating-point value (for example, using a CAST specification), the default decimal separator character in effect when the statement was prepared is used to interpret the string.
A character string is a sequence of bytes. The length of the string is the number of bytes in the sequence. If the length is zero, the value is called the empty string. The empty string should not be confused with the null value.
All values of a fixed-length character-string column have the same length. This is determined by the length attribute of the column. The length attribute must be between 1 through 32766 inclusive.
The types of varying-length character strings are:
The values of a column with any one of these string types can have different lengths. The length attribute of the column determines the maximum length a value can have.
For a VARCHAR column, the length attribute must be between 1 through 32740 inclusive. For a CLOB column, the length attribute must be between 1 through 2 147 483 647 inclusive. For more information about CLOBs, see Large objects.
For the restrictions that apply to the use of long varying-length strings, see Limitations on use of strings.
Each character string is further defined as one of:
The database manager does not recognize subclasses of double-byte characters, and it does not assign any specific meaning to particular double-byte codes. However, if you choose to use mixed data, then two single-byte EBCDIC codes are given special meanings:
In order for the database manager to recognize double-byte characters in a mixed data character string, the following condition must be met:
The pairing is detected as the string is read from left to right. The code X'0E' is recognized as a shift out character if X'0F' occurs later; otherwise, it is invalid. The first X'0F' following the X'0E' that is on a double-byte boundary is the paired shift-in character. Any X'0F' that is not on a double-byte boundary is not recognized.
There must be an even number of bytes between the paired characters, and each pair of bytes is considered to be a double-byte character. There can be more than one set of paired shift-out and shift-in characters in the string.
The length of a mixed data character string is its total number of bytes, counting two bytes for each double-byte character and one byte for each shift-out or shift-in character.
When the job CCSID indicates that DBCS is allowed, CREATE TABLE will create character columns as DBCS-Open fields, unless FOR BIT DATA, FOR SBCS DATA, or an SBCS CCSID is specified. The SQL user will see these as character fields, but the system database support will see them as DBCS-Open fields. For a definition of a DBCS-Open field, see the Database Programming book.
A graphic string is a sequence of two-byte characters. The length of the string is the number of its characters. Like character strings, graphic strings can be empty.
All values of a fixed-length graphic-string column have the same length, which is determined by the length attribute of the column. The length attribute must be between 1 through 16383 inclusive.
The types of varying-length graphic strings are:
The values of a column with any one of these string types can have different lengths. The length attribute of the column determines the maximum length a value can have.
For a VARGRAPHIC column, the length attribute must be between 1 through 16370 inclusive. For a DBCLOB column, the length attribute must be between 1 through 1 073 741 823 inclusive. For more information about DBCLOBs, see Large objects.
For the restrictions that apply to the use of long varying-length strings, see Limitations on use of strings.
Although fixed-length graphic-string variables cannot be defined in PL/I, COBOL/400, and RPG/400, a character-string variable will be treated like a fixed-length graphic-string variable if it was generated in the source from a GRAPHIC column in the external definition of a file.
Each graphic string is further defined as one of:
Every DBCS graphic string has a CCSID that identifies a double-byte coded character set. If necessary, a DBCS graphic string is converted before it is used in an operation with a DBCS graphic string that has a different DBCS CCSID.
When graphic-string variables are not explicitly tagged with a CCSID, the associated DBCS CCSID for the job CCSID is used. If no associated DBCS CCSID exists, the variable is tagged with 65535. A graphic-string variable is never implicitly tagged with a UTF-16 or UCS-2 CCSID. See the DECLARE VARIABLE statement for information on how to tag a graphic variable with a CCSID.
A binary string is a sequence of bytes. The length of a binary string is the number of bytes in the sequence. A binary string has a CCSID of 65535.
All values of a fixed-length binary-string column have the same length. This is determined by the length attribute of the column. The length attribute must be between 1 through 32766 inclusive.
The types of varying-length binary strings are:
The values of a column with any one of these string types can have different lengths. The length attribute of the column determines the maximum length a value can have.
For a VARBINARY column, the length attribute must be between 1 through 32740 inclusive. For a BLOB column, the length attribute must be between 1 through 2 147 483 647 bytes inclusive. For more information about BLOBs, see Large objects.
A variable with a binary string type can be defined in all host languages except REXX, RPG/400, and COBOL/400.
Although binary strings and FOR BIT DATA character strings might be used for similar purposes, the two data types are not compatible. The BINARY, BLOB, and VARBINARY functions can be used to change a FOR BIT DATA character string into a binary string.
The term large object and the generic acronym LOB are used to refer to any CLOB, DBCLOB, or BLOB data type.
Since LOB values can be very large, the transfer of these values from the database server to client application program variables can be time consuming. Also, application programs typically process LOB values a piece at a time, rather than as a whole. For these cases, the application can reference a LOB value via a large object locator (LOB locator). 19
A large object locator or LOB locator is a variable with a value that represents a single LOB value in the database server. LOB locators were developed to provide users with a mechanism by which they could easily manipulate very large objects in application programs without requiring them to store the entire LOB value on the client machine where the application program may be running.
For example, when selecting a LOB value, an application program could select the entire LOB value and place it into an equally large variable (which is acceptable if the application program is going to process the entire LOB value at once), or it could instead select the LOB value into a LOB locator. Then, using the LOB locator, the application program can issue subsequent database operations on the LOB value by supplying the locator value as input. The resulting output of the locator operation, for example the amount of data assigned to a client variable, would then typically be a small subset of the input LOB value.
LOB locators may also represent more than just base values; they can also represent the value associated with a LOB expression. For example, a LOB locator might represent the value associated with:
SUBSTR(lob_value_1 CONCAT lob_value_2 CONCAT lob_value_3, 42, 6000000)
For non-locator-based host variables in an application program, when a null value is selected into that host variable, the indicator variable is set to -1, signifying that the value is null. In the case of LOB locators, however, the meaning of indicator variables is slightly different. Since a LOB locator host variable itself can never be null, a negative indicator variable value indicates that the LOB value represented by the LOB locator is null. The null information is kept local to the client by virtue of the indicator variable value -- the server does not track null values with valid LOB locators.
It is important to understand that a LOB locator represents a value, not a row or location in the database. Once a value is selected into a LOB locator, there is no operation that one can perform on the original row or table that will affect the value which is referenced by the LOB locator. The value associated with a LOB locator is valid until the transaction ends, or until the LOB locator is explicitly freed, whichever comes first.
A LOB locator is only a mechanism used to refer to a LOB value during a transaction; it does not persist beyond the transaction in which it was created. Also, it is not a database type; it is never stored in the database and, as a result, cannot participate in views or check constraints. However, since a locator is a representation of a LOB type, there are SQLTYPEs for LOB locators so that they can be described within an SQLDA structure that is used by FETCH, OPEN, CALL, and EXECUTE statements.
For the restrictions that apply to the use of LOB strings, see Limitations on use of strings.
The following varying-length string data types cannot be referenced in certain contexts:
| Context of usage | LOB (CLOB, DBCLOB, or BLOB) |
|---|---|
| A GROUP BY clause | Not allowed |
| An ORDER BY clause | Not allowed |
| A CREATE INDEX statement | Not allowed |
| A SELECT DISTINCT statement | Not allowed |
| A subselect of a UNION, EXCEPT, or INTERSECT without the ALL keyword | Not allowed |
| The definition of primary, unique, and foreign keys | Not allowed |
| Parameters of built-in functions | Some functions that allow varying-length character strings, varying-length graphic strings, or both types of strings as input arguments do not support CLOB or DBCLOB strings, or both as input. See the description of the individual functions in Built-in functions for the data types that are allowed as input to each function. |
Although datetime values can be used in certain arithmetic and string operations and are compatible with certain strings, they are neither strings nor numbers. However, strings can represent datetime values; see String representations of datetime values.
A date is a three-part value (year, month, and day) designating a point in time under the Gregorian calendar20, which is assumed to have been in effect from the year 1 A.D. The range of the year part is 0001 to 9999. The date formats *JUL, *MDY, *DMY, and *YMD can only represent dates in the range 1940 through 2039. The range of the month part is 1 to 12. The range of the day part is 1 to x, where x is 28, 29, 30, or 31, depending on the month and year.
The internal representation of a date is a string of 4 bytes that contains an integer. The integer (called the Scaliger number) represents the date.
The length of a DATE column as described in the SQLDA is 6, 8, or 10 bytes, depending on which format is used. These are the appropriate lengths for string representations for the value.
A time is a three-part value (hour, minute, and second) designating a time of day using a 24-hour clock. The range of the hour part is 0 to 24, while the range of the minute and second parts is 0 to 59. If the hour is 24, the minute and second specifications are both zero.
The internal representation of a time is a string of 3 bytes. Each byte consists of two packed decimal digits. The first byte represents the hour, the second byte the minute, and the last byte the second.
The length of a TIME column as described in the SQLDA is 8 bytes, which is the appropriate length for a string representation of the value.
A timestamp is a seven-part value (year, month, day, hour, minute, second, and microsecond) that designates a date and time as defined previously, except that the time includes a fractional specification of microseconds.
The internal representation of a timestamp is a string of 10 bytes. The first 4 bytes represent the date, the next 3 bytes the time, and the last 3 bytes the microseconds (the last 3 bytes contain 6 packed digits).
The length of a TIMESTAMP column as described in the SQLDA is 26 bytes, which is the appropriate length for the string representation of the value.
Character string variables are normally used to contain date, time, and timestamp values. However, date, time, and timestamp variables can also be specified in ILE COBOL and ILE RPG. Date, time, and timestamp variables can also be specified in Java as java.sql.Date, java.sql.Time, and java.sql.Timestamp respectively.
Values whose data types are DATE, TIME, or TIMESTAMP are represented in an internal form that is transparent to the user of SQL. Dates, times, and timestamps, however, can also be represented by character or UTF-16 or UCS-2 graphic strings. Only ILE RPG and ILE COBOL support datetime variables. To be retrieved, a datetime value can be assigned to a string variable. The format of the resulting string will depend on the default date format and the default time format in effect when the statement was prepared. The default date and time formats are set based on the date format (DATFMT), the date separator (DATSEP), the time format (TIMFMT), and the time separator (TIMSEP) parameters.
When a valid string representation of a datetime value is used in an operation with an internal datetime value, the string representation is converted to the internal form of the date, time, or timestamp before the operation is performed. If the CCSID of the string represents a foreign encoding scheme (for example, ASCII), it is first converted to the coded character set identified by the default CCSID before the string is converted to the internal form of the datetime value.
The following sections define the valid string representations of datetime values.
A string representation of a date is a character or a UCS-2 or UTF-16 graphic string that starts with a digit and has a length of at least 6 characters. Trailing blanks can be included. Leading zeros can be omitted from the month and day portions when using the IBM® SQL standard formats. Each IBM SQL standard format is identified by name and includes an associated abbreviation (for use by the CHAR function). Other formats do not have an abbreviation to be used by the CHAR function. The separators for two-digit year formats are controlled by the date separator (DATSEP) parameter. Valid string formats for dates are listed in Table 5.
The database manager recognizes the string as a date when it is either:
| Format Name | Abbreviation | Date Format | Example |
|---|---|---|---|
| ANSI/ISO SQL standard date format (–) | – | DATE 'yyyy-mm-dd' | DATE '1987-10-12' |
| International Standards Organization (*ISO) | ISO | 'yyyy-mm-dd' | '1987-10-12' |
| IBM USA standard (*USA) | USA | 'mm/dd/yyyy' | '10/12/1987' |
| IBM European standard (*EUR) | EUR | 'dd.mm.yyyy' | '12.10.1987' |
| Japanese industrial standard Christian era (*JIS) | JIS | 'yyyy-mm-dd' | '1987-10-12' |
| Unformatted Julian | – | 'yyyyddd' | '1987285' |
| Julian (*JUL) | – | 'yy/ddd' | '87/285' |
| Month, day, year (*MDY) | – | 'mm/dd/yy' | '10/12/87' |
| Day, month, year (*DMY) | – | 'dd/mm/yy' | '12/10/87' |
| Year, month, day (*YMD) | – | 'yy/mm/dd' | '87/12/10' |
The default date format can be specified through the following interfaces:
| SQL Interface | Specification |
|---|---|
| Embedded SQL | The DATFMT and DATSEP parameters are specified
on the Create SQL Program (CRTSQLxxx) commands. The SET OPTION statement can
also be used to specify the DATFMT and DATSEP parameters within the source
of a program containing embedded SQL.
|
| Interactive SQL and Run SQL Statements | The DATFMT and DATSEP parameters on the Start
SQL (STRSQL) command or by changing the session attributes. The DATFMT and
DATSEP parameters on the Run SQL Statements (RUNSQLSTM) command.
|
| Call Level Interface (CLI) on the server | SQL_ATTR_DATE_FMT and SQL_ATTR_DATE_SEP environment
or connection variables
|
| JDBC or SQLJ on the server using IBM Developer Kit for Java | Date Format and Date Separator connection
property
|
| ODBC on a client using the iSeries Access Family ODBC Driver | Date Format and Date Separator in the Advanced
Server Options in ODBC Setup
|
| JDBC on a client using the IBM Toolbox for Java | Format in JDBC Setup
|
A string representation of a time is a character or a UCS-2 or UTF-16 graphic string that starts with a digit and has a length of at least 4 characters. Trailing blanks can be included; a leading zero can be omitted from the hour part of the time and seconds can be omitted entirely. If you choose to omit seconds, an implicit specification of 0 seconds is assumed. Thus, 13.30 is equivalent to 13.30.00.
Valid string formats for times are listed in Table 7. Each IBM SQL standard format is identified by name and includes an associated abbreviation (for use by the CHAR function). The other format (*HMS) does not have an abbreviation to be used by the CHAR function. The separator for the *HMS format is controlled by the time separator (TIMSEP) parameter.
The database manager recognizes the string as a time when it is either:
| Format Name | Abbreviation | Time Format | Example |
|---|---|---|---|
| ANSI/ISO SQL standard time format (–) | – | TIME 'hh:mm:ss' | TIME '13:30:05' |
| International Standards Organization (*ISO) | ISO | 'hh.mm.ss' 21 | '13.30.05' |
| IBM USA standard (*USA) | USA | 'hh:mm AM' (or PM) | '1:30 PM' |
| IBM European standard (*EUR) | EUR | 'hh.mm.ss' | '13.30.05' |
| Japanese industrial standard Christian era (*JIS) | JIS | 'hh:mm:ss' | '13:30:05' |
| Hours, minutes, seconds (*HMS) | – | 'hh:mm:ss' | '13:30:05' |
The following additional rules apply to the USA time format:
In the USA format, using the ISO format of the 24-hour clock, the correspondence between the USA format and the 24-hour clock is as follows:
| USA Format | 24-Hour Clock |
|---|---|
| 12:01 AM through 12:59 AM | 00.01.00 through 00.59.00 |
| 01:00 AM through 11:59 AM | 01:00.00 through 11:59.00 |
| 12:00 PM (noon) through 11:59 PM | 12:00.00 through 23.59.00 |
| 12:00 AM (midnight) | 24.00.00 |
| 00:00 AM (midnight) | 00.00.00 |
The default time format can be specified through the following interfaces:
| SQL Interface | Specification |
|---|---|
| Embedded SQL | The TIMFMT and TIMSEP parameters are specified
on the Create SQL Program (CRTSQLxxx) commands. The SET OPTION statement can
also be used to specify the TIMFMT and TIMSEP parameters within the source
of a program containing embedded SQL.
|
| Interactive SQL and Run SQL Statements | The TIMFMT and TIMSEP parameters on the Start
SQL (STRSQL) command or by changing the session attributes. The TIMFMT and
TIMSEP parameters on the Run SQL Statements (RUNSQLSTM) command.
|
| Call Level Interface (CLI) on the server | SQL_ATTR_TIME_FMT and SQL_ATTR_TIME_SEP environment
or connection variables
|
| JDBC or SQLJ on the server using IBM Developer Kit for Java | Time Format and Time Separator connection
property object
|
| ODBC on a client using the iSeries Access Family ODBC Driver | Time Format and Time Separator in the Advanced
Server Options in ODBC Setup
|
| JDBC on a client using the IBM Toolbox for Java | Format in JDBC Setup
|
A string representation of a timestamp is a character or a UCS-2 or UTF-16 graphic string that starts with a digit and has a length of at least 16 characters. The complete string representation of a timestamp has one of the following forms:
| Format Name | Time Format | Example |
|---|---|---|
| ANSI/ISO SQL standard | TIMESTAMP 'yyyy-mm-dd hh:mm:ss.nnnnnn' | TIMESTAMP '1990-03-02 08:30:00.010000' |
| ISO timestamp | 'yyyy-mm-dd hh:mm:ss.nnnnnn' | '1990-03-02 08:30:00.010000' |
| IBM SQL | 'yyyy-mm-dd-hh.mm.ss.nnnnnn' | '1990-03-02-08.30.00.010000' |
| 14–character form | 'yyyymmddhhmmss' | '19900302083000' |
Trailing blanks can be included. Leading zeros can be omitted from the month, day, and hour part of the timestamp when using the timestamp form with separators. Trailing zeros can be truncated or omitted entirely from microseconds. If you choose to omit any digit of the microseconds portion, an implicit specification of 0 is assumed. Thus, 1990-3-2-8.30.00.10 is equivalent to 1990-03-02-08.30.00.100000.
A timestamp whose time part is 24.00.00.000000 is also accepted.
A DataLink value is an encapsulated value that contains a logical reference from the database to a file stored outside the database. The attributes of this encapsulated value are as follows:
The characters used in a DataLink value are limited to the set defined for a URL. These characters include the uppercase (A through Z) and lower case (a through z) letters, the digits (0 through 9) and a subset of special characters ($, -, _, @, ., &, +, !, *, ", ', (, ), =, ;, /, #, ?, :, space, and comma).
The first four attributes are collectively known as the linkage attributes. It is possible for a DataLink value to have only a comment attribute and no linkage attributes. Such a value may even be stored in a column but, of course, no file will be linked to such a column.
It is important to distinguish between these DataLink references to files and the LOB file reference variables described in References to LOB file reference variables. The similarity is that they both contain a representation of a file. However:
Built-in scalar functions are provided to build a DataLink value (DLVALUE) and to extract the encapsulated values from a DataLink value (DLCOMMENT, DLLINKTYPE, DLURLCOMPLETE, DLURLPATH, DLURLPATHONLY, DLURLSCHEME, DLURLSERVER).
A row ID is a value that uniquely identifies a row in a table. A column or a variable can have a row ID data type. A ROWID column enables queries to be written that navigate directly to a row in the table. Each value in a ROWID column must be unique. The database manager maintains the values permanently, even across table reorganizations. When a row is inserted into the table, the database manager generates a value for the ROWID column unless one is supplied. If a value is supplied, it must be a valid row ID value that was previously generated by either DB2 UDB for z/OS or DB2 UDB for iSeries.
The internal representation of a row ID value is transparent to the user. The value is never subject to CCSID conversion because it is considered to contain BIT data. The length attribute of a ROWID column is 40.
A distinct type is a user-defined data type that shares its internal representation with a built-in data type (its "source type"), but is considered to be a separate and incompatible type for most operations. For example, the semantics for a picture type, a text type, and an audio type that all use the built-in data type BLOB for their internal representation are quite different. A distinct type is created using CREATE DISTINCT TYPE.
For example, the following statement creates a distinct type named AUDIO:
CREATE DISTINCT TYPE AUDIO AS BLOB (1M)
Although AUDIO has the same representation as the built-in data type BLOB, it is considered to be a separate type that is not comparable to a BLOB or to any other type. This inability to compare AUDIO to other data types allows functions to be created specifically for AUDIO and assures that these functions cannot be applied to other data types (such as pictures or text).
The name of a distinct type is qualified with a schema name. The implicit schema name for an unqualified name depends upon the context in which the distinct type appears. If an unqualified distinct type name is used:
A distinct type does not automatically acquire the functions and operators of its source type, since these may not be meaningful. (For example, the LENGTH function of the AUDIO type might return the length of its object in seconds rather than in bytes.) Instead, distinct types support strong typing. Strong typing ensures that only the functions and operators that are explicitly defined for a distinct type can be applied to that distinct type. However, a function or operator of the source type can be applied to the distinct type by creating an appropriate user-defined function. The user-defined function must be sourced on the existing function that has the source type as a parameter. For example, the following series of SQL statements shows how to create a distinct type named MONEY based on data type DECIMAL(9,2), how to define the + operator for the distinct type, and how the operator might be applied to the distinct type:
CREATE DISTINCT TYPE MONEY AS DECIMAL(9,2) WITH COMPARISONS CREATE FUNCTION "+"(MONEY,MONEY) RETURNS MONEY SOURCE "+"(DECIMAL(9,2),DECIMAL(9,2)) CREATE TABLE SALARY_TABLE (SALARY MONEY, COMMISSION MONEY) SELECT "+"(SALARY, COMMISSION) FROM SALARY_TABLE
A distinct type is subject to the same restrictions as its source type. For example, a table can only have one ROWID column. Therefore, a table with a ROWID column cannot also have a column with distinct type that is sourced on a row ID.
The comparison operators are automatically generated for distinct types, except for distinct types that are sourced on a DataLink. In addition, the database manager automatically generates functions for a distinct type that support casting from the source type to the distinct type and from the distinct type to the source type. For example, for the AUDIO type created above, these are the generated cast functions:
| Name of generated cast function | Parameter list | Returns data type |
|---|---|---|
| schema-name.BLOB | schema-name.AUDIO | BLOB |
| schema-name.AUDIO | BLOB | schema-name.AUDIO |