A string is a sequence of bytes that may represent characters. Within a string, all the characters are represented by a common coding representation. In some cases, it might be necessary to convert these characters to a different coding representation. The process of conversion is known as character conversion.6
Character conversion can occur when an SQL statement is executed remotely. Consider, for example, these two cases:
In either case, the string could have a different representation at the sending and receiving systems. Conversion can also occur during string operations on the same system.
Note that SQL statements are strings and are therefore subject to character conversion.
The following list defines some of the terms used when discussing character conversion.
A UTF-8 character can be 1,2,3 or 4 bytes in length. A UTF-8 data string can contain any combination of SBCS and DBCS data, including surrogates and combining characters.
UCS-2 is a subset of UTF-16. UCS-2 is identical to UTF-16 except that UTF-16 also supports combining characters and surrogates. Since UCS-2 is a simpler form of UTF-16, UCS-2 data will typically perform better than UTF-16.8
Both UTF-8 and UTF-16 data can contain combining characters. Combining character support allows a resulting character to be comprised of more than one character. After the first character, hundreds of different non-spacing accent characters (umlauts, accents, etc.) can follow in the data string. The resulting character may already be defined in the character set. In this case, there are multiple representations for the same character. For example, in UTF-16, an é can be represented either by X'00E9' (the normalized representation) or X'00650301' (the non-normalized combining character representation).
Since multiple representations of the same character will not compare equal, it is usually not a good idea to store both forms of the characters in the database. Normalization is a process that replaces the string of combining characters with equivalent characters that do not include combining characters. After normalization has occurred, only one representation of any specific character will exist in the data. For example, in UTF-16, any instances of X'00650301' (the non-normalized combining character representation of é ) will be converted to X'00E9' (the normalized representation of é ).9
Both UTF-8 and UTF-16 can contain 4 byte characters called surrogates. Surrogates are 4 byte sequences that can address one million more characters than would be available in a 2 byte character set.
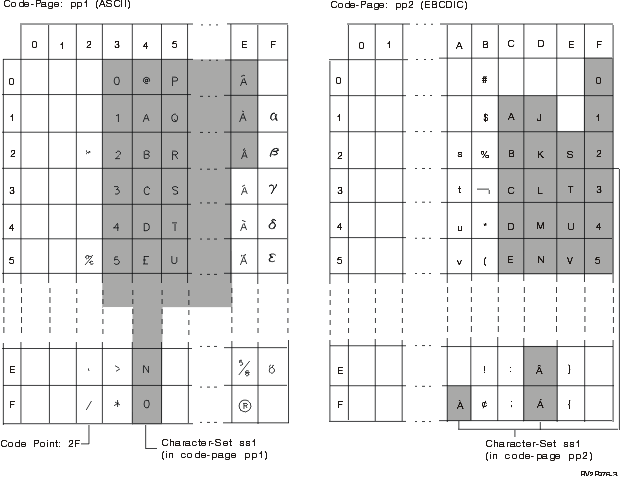
The following example shows how a typical character set might map to different code points in two different code pages.
Even with the same encoding scheme there are many different coded character sets, and the same code point can represent a different character in different coded character sets. Furthermore, a byte in a character string does not necessarily represent a character from a single-byte character set (SBCS). Character strings are also used for mixed data (a mixture of single-byte characters and double-byte characters) and for data that is not associated with any character set (called bit data). This is not the case with graphic strings; the database manager assumes that every pair of bytes in every graphic string represents a character from a double-byte character set (DBCS) or universal coded character set (UCS-2 or UTF-16).
A coded character set identifier (CCSID) in a native encoding scheme is one of the coded character sets in which data may be stored at that site. A CCSID in a foreign encoding scheme is one of the coded character sets in which data cannot be stored at that site. For example, DB2 UDB for iSeries can store data in a CCSID with an EBCDIC encoding scheme, but not in an ASCII encoding scheme.
A variable containing data in a foreign encoding scheme is always converted to a CCSID in the native encoding scheme when the variable is used in a function or in the select-list. A variable containing data in a foreign encoding scheme is also effectively converted to a CCSID in the native encoding scheme when used in comparison or in an operation that combines strings. Which CCSID in the native encoding scheme the data is converted to is based on the foreign CCSID and the default CCSID.
For details on character conversion, see:
If CCSID conversion is necessary to evaluate the result set of a query, the query cannot contain:
IBM®'s Character Data Representation Architecture (CDRA) deals with the differences in string representation and encoding. The Coded Character Set Identifier (CCSID) is a key element of this architecture. A CCSID is a 2-byte (unsigned) binary number that uniquely identifies an encoding scheme and one or more pairs of character sets and code pages.
A CCSID is an attribute of strings, just as length is an attribute of strings. All values of the same string column have the same CCSID.
In each database manager, character conversion involves the use of a CCSID Conversion Selection Table. The Conversion Selection Table contains a list of valid source and target combinations. For each pair of CCSIDs, the Conversion Selection Table contains information used to perform the conversion from one coded character set to the other. This information includes an indication of whether conversion is required. (In some cases, no conversion is necessary even though the strings involved have different CCSIDs.)
Different types of conversions may be supported by the database manager. Round-trip conversions attempt to preserve characters in one CCSID that are not defined in the target CCSID so that if the data is subsequently converted back to the original CCSID, the same original characters result. Enforced subset match conversions do not attempt to preserve such characters. For more information, see IBM's Character Data Representation Architecture (CDRA).
Every application server and application requester has a default CCSID (or default CCSIDs in installations that support DBCS data). The CCSID of the following types of strings is determined at the current server:
If one of the types of strings above is used in a CREATE VIEW statement, the default CCSID is determined at the time the view is created.
In a distributed application, the default CCSID of variables is determined by the application requester. In a non-distributed application, the default CCSID of variables is determined by the application server. On i5/OS, the default CCSID is determined by the CCSID job attribute. For more information about CCSIDs, see the Work with CCSIDs topic in the Globalization section of the iSeries Information Center.