Input spooling takes the information from the input device, prepares the job for scheduling, and places an entry in a job queue. Using input spooling, you can typically shorten job run time, increase the number of jobs that can be run sequentially, and improve device throughput.
The main elements of input spooling are:
- Job queue: An ordered list of batch jobs submitted to the server for running and from which batch jobs are selected to run.
- Reader: A function that takes jobs from an input device or database file and places them on a job queue.
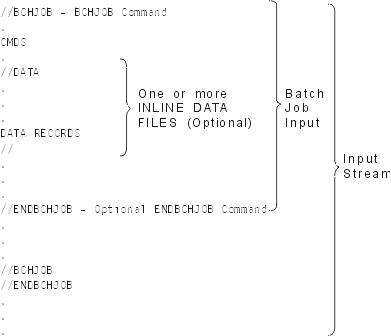
When a batch job is read from an input source by a reader, the commands in the input stream are stored in the server as requests for the job, the inline data is spooled as inline data files, and an entry for the job is placed on a job queue. The job information remains stored in the server where it was placed by the reader until the job entry is selected from the job queue for processing by a subsystem.
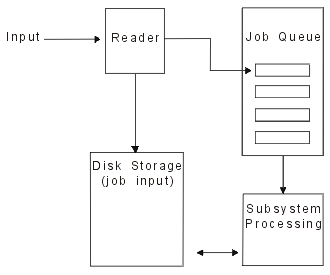
You can use the reader functions to read an input stream from diskette or database files.
- *RDR: The job queue is selected from the JOBQ parameter on the Start database reader (STRDBRDR) command.
- *JOBD: The job queue is selected from the JOBQ parameter in the job description.
- A specific job queue: The specified queue is used.
For jobs with small input streams, you might improve server performance by not using input spooling. The Submit Job (SBMJOB) command reads the input stream and places the job on the job queue in the appropriate subsystem, bypassing the spooling subsystem and reader operations.
If your job requires a large input stream to be read, you should use input spooling (Start Diskette Reader STRDKTRDR or Start Database ReaderSTRDBRDR command) to allow the job to be input independent of when the job is actually processed.