 Gateway replication across networks.
Gateway replication across networks.
Replication provides two main benefits:
Specific entries in the directory are identified as the roots of replicated subtrees, by adding the ibm-replicationContext objectclass to them. Each subtree is replicated independently. The subtree continues down through the directory information tree (DIT) until reaching the leaf entries or other replicated subtrees. Entries are added below the root of the replicated subtree to contain the replication topology information. These entries are one or more replica group entries, under which are created replica subentries. Associated with each replica subentry are replication agreements that identify the servers that are supplied (replicated to) by each server, as well as defining the credentials and schedule information.
Through replication, a change made to one directory is propagated to one or more additional directories. In effect, a change to one directory shows up on multiple different directories. The IBM Directory supports an expanded master-subordinate replication model. Replication topologies are expanded to include:
Gateway replication across networks.The advantage of replicating by subtrees is that a replica does not need to replicate the entire directory. It can be a replica of a part, or subtree, of the directory.
The expanded model changes the concept of master and replica. These terms no longer apply to servers, but rather to the roles that a server has regarding a particular replicated subtree. A server can act as a master for some subtrees and as a replica for others. The term, master, is used for a server that accepts client updates for a replicated subtree. The term, replica, is used for a server that only accepts updates from other servers designated as a supplier for the replicated subtree.
The types of servers as defined by function are master/peer, cascading, gateway, and replica.
If the replication fails, it is repeated even if the master is restarted. The Manage Queues window in the Web administration tool can be used to check for failing replication.
You can request updates on a replica server, but the update is actually forwarded to the master server by returning a referral to the client. If the update is successful, the master server then sends the update to the replicas. Until the master has completed replication of the update, the change is not reflected on the replica server where it was originally requested. Changes are replicated in the order in which they are made on the master.
If you are no longer using a replica, you must remove the replication agreement from the supplier. Leaving the definition causes the server to queue up all updates and use unnecessary directory space. Also, the supplier continues trying to contact the missing consumer to retry sending the data.
Gateway replication
Gateway replication uses gateway servers to collect and distribute
replication information effectively across a replicating network. The primary
benefit of gateway replication is the reduction of network traffic. Gateway
servers must be masters (writable).
The following figure illustrates how gateway replication works:
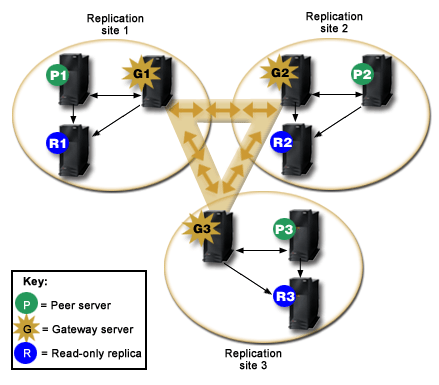
The replicating network in the preceding figure contains three replication
sites, each containing a gateway server. The gateway server collects replication
updates from the peer/master servers in the replication site where it resides
and sends the updates to all the other gateway servers within the replicating
network. It also collects replication updates from other gateway servers in
the replication network and sends those updates to the peers/masters and replicas
in the replication site where it resides.
Gateway servers use server IDs and consumer IDs to determine
which updates are sent to other gateway servers in the replicating network
and which updates are sent to local servers within the replication site.
To set up gateway replication, you must create at least two
gateway servers. The creation of a gateway server establishes a replication
site. You must then create replication agreements between the gateway and
any masters/peers and replicas you want to include in that gateway's replication
site.
Gateway servers must be masters (writable). If you attempt to
add the gateway object class, ibm-replicaGateway, to a subentry that is not
a master, an error message is returned.
There are two methods for creating a gateway server. You can: