This example, using UCS-2 as the CCSID of DATABASE1, shows how data integrity is maintained both in storing and retrieving data.
As in the example of Display data without Unicode information, one user is English using CCSID 37 and the other user is Greek using CCSID 875.
DATABASE1 is used as in the previous example. However DATABASE1 is now defined with CCSID 13488. (13488 is a UCS-2 CCSID.)
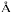 alson
alson- Gifford
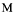
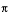
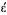
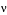
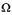
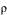
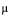
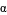
The key difference in using UCS-2 as the CCSID of DATABASE1 is that data integrity is maintained for each user who inputs data to the database. That is each character, regardless of the CCSID of the inputting device, is stored with a unique code point. (Remember that in this example the CCSID of DATABASE1 is 13488.)
- Name
- CCSID 13488 Stored Code Point (Hexadecimal)
- alson
- 00C5 . . .
- Gifford
- 0047 . . .
-
- 03A9 . . .
-
- 039C . . .
Assume that the Greek user wants to find all names beginning with . The following SQL
statement can provide one name, ,
as compared to two in the previous example:
Select from DATABASE1 where Substr(name,1,1) = ' '
The reason for this is that each character stored in a UCS-2 tagged database
has a unique code point. This contrasts to the example of Display data without
Unicode information that had the first character in alson stored with the same code point as the first
character in