A distributed file is a database file that is spread across multiple iSeries™ servers. This section describes some of the main concepts that are used in discussing the creation and use of distributed files by DB2® Multisystem.
Each server that has a piece of a distributed file is called a node. Each server is identified by the name that is defined for it in the relational database directory.
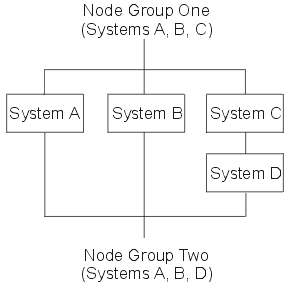
A group of systems that contains one or more distributed files is called a node group. A node group is a system object that contains the list of nodes across which the data is distributed. A system can be a node in more than one node group.
A file is distributed across all the systems in a node group through partitioning. Table partitioning, further described in Partitioned tables, applies to tables partitioned on a single system.
A partition number is a number from 0 to 1023. Each partition number is assigned to a node in the node group. Each node can be assigned many partition numbers. The correlation between nodes and partition numbers is stored in a partition map. The partition map is also stored as part of the node group object. You can provide the partition map when you create a node group; otherwise, the system generates a default map.
You define a partition map by using a partitioning file. A partitioning file is a physical file that defines a node number for each partition number.
A partitioning key consists of one or more fields in the file that is being distributed. The partitioning key is used to determine which node in the node group is to physically contain rows with certain values. This is done by using hashing, an operating system function that takes the value of the partitioning key for a record and maps it to a partition number. The node corresponding to that partition number is used to store the record.
The following example shows what partition number and nodes might look like for a distributed table for two systems. The table has a partitioning key of LASTNAME.
In the partition map, partition number 0 contains SYSA, partition number 1 contains node SYSB, partition number 2 contains SYSA, and partition number 3 contains SYSB. This pattern is repeated.
The hashing of the partitioning key determines a number that corresponds to a partition number. For example, a record that has a value of Andrews might hash to partition number 1. A record that has a value of Anderson might hash to partition number 2. If you refer to the partition map shown in Table 1, records for partition number 1 are stored at SYSB, while records for partition number 2 are stored at SYSA.