 There are two
models of cluster resource groups.
There are two
models of cluster resource groups.
The information provided here includes:
The Cluster Resource Group (CRG) function within a cluster is to:
Any cluster resource group API may be called on any node in the cluster. Most cluster resource group APIs have an asynchronous behavior.
The majority of the cluster resource group APIs require that Cluster Resource Services be active. This is necessary to ensure consistency of cluster resource groups across the cluster. Each API indicates whether or not Cluster Resource Services needs to be active for the API to complete successfully.
Cluster Resource Services maintains synchronous copies of cluster resource groups (perceptively and operationally identical) on all nodes in the group's recovery domain. When a node joins the cluster or when a cluster partition is resolved, the cluster resource group object is reconciled. This may mean copying the cluster resource group object from some node already in the cluster to the joining node or from the primary partition to nodes in the secondary partition. See Partition Rules for details on primary and secondary partitions.
There are two
models of cluster resource groups.
 .
.
Cluster resource group objects are either data resiliency, application
resiliency, device resiliencyor peer
resiliency.
Data resiliency represents multiple copies of
data maintained on more than one node in a cluster. Application resiliency
enables an application (program) to be restarted on either the same or a
different node in the cluster. This is made possible by a Takeover IP Address.
Device resiliency allows devices such as auxiliary storage pools to be switched
from one node in a cluster to another node.Peer
resiliency represents resources being accessed by mutliple clients.
.
Cluster resource groups contain a recovery domain. A Recovery Domain is that set of cluster nodes which, for a particular cluster resource group, describes the access points of the cluster resource. Each node in the recovery domain is assigned a role that reflects its point of access:
| Primary Node | The cluster node that is the point of access for
the resilient cluster resource. For a replicated resource, the primary node
also contains the principal copy of a resource. If this node fails, all cluster
resource group objects having this node as the primary access point will
failover to a backup node. This role
is allowed for primary-backup model cluster resource groups.
|
| Backup Nodes | Cluster nodes that will take over the role of
primary access if the present primary node fails. For a replicated cluster
resource, this cluster node contains a copy of that resource. In the case of a
data cluster resource group, copies of the data are kept current with
replication.This role
is allowed for primary-backup model cluster resource groups. |
| Replicate Nodes | Cluster nodes that has copies of cluster
resources. The node
it is unable
to assume the role of primary, backup, or peer.
|
| Peer Nodes |
All nodes have the same copy of the cluster
resources. A node defined with this role is available to be the active point of access
for the cluster resources. This role is only supported for peer cluster
resource groups.
|
Some Cluster Control APIs cause cluster resource group actions to be taken. For example, an End Cluster Node (QcstEndClusterNode) API will cause the active cluster resource groups on that node to be ended and the Cluster Resource Group exit program to be called. In these instances, the success indicator returned by the exit program will be ignored. The operations will always be considered successful.
A cluster resource group has a recovery domain of one or more cluster nodes. Each cluster node within the recovery domain has two roles: preferred and current. The two node roles need not be the same. When a cluster resource group is initially created, the preferred and the current roles are the same. When a cluster resource group is created, a cluster resource group job is started on each active node in the cluster and a *CRG object will be created on each recovery domain node.
The current role of a node in the recovery domain is changed as a result of operations occurring within the cluster (for example nodes ending, nodes starting, and nodes failing).
For primary-backup model cluster
resource groups
For peer model cluster resource groups:
The preferred role of a node in the cluster is changed only by running the following APIs:
Changes to the node roles are done independently. The role specified for a node in any of these APIs will be assigned to both the current and preferred roles of the node.
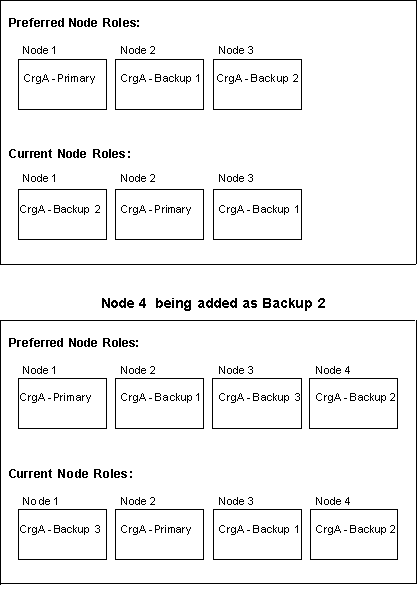
Example of node roles for a primary-backup model cluster resource group.
.
For example, the recovery domain of a
primary-backup model
cluster resource group
object has preferred roles of N1-primary, N2-backup1, and N3-backup2, but the
current roles are N1-backup2, N2-primary, and N3-backup1. N4 is being added as
backup2. Therefore, the preferred roles of the nodes are N1-primary,
N2-backup1, N3-backup3, and N4-backup2, and the current roles are N1-backup3,
N2-primary, N3-backup1, and N4-backup2.
Example of node roles for a peer model cluster resource group.
In this example, the recovery domain of a
peer model
cluster resource group
object preferred roles are N1-peer, and N2-replicate, but the
current roles are N1-peer, and N2-replicate. N3 is being added as
peer. Therefore, the preferred roles of the nodes are N1-peer,
N2-replicate, and N3-peer, and the current roles are N1-peer,
N2-replicate, and N3-peer. Notice that the recovery domain is reordered when
another node is added to the recovery domain with a role of peer.

Every data or application cluster resource group has an associated exit program. A device cluster resource group can also have an exit program but one is not required. This exit program will be called for each of the different action codes listed under the Cluster Resource Group exit program. The exit program is called from a separate job using the user profile supplied when the cluster resource group is created. See Cluster Resource Group exit program for a description of the conditions that cause the exit program to be called.
The user exit program will be restricted from calling some of the APIs. Each API specifies the user exit program restrictions.
Application
Takeover IP AddressAn
img src="delta.gif" alt="Start of change">application
takeover IP address is a high availability mechanism used to insulate
clients from application server outages. The concept is to use IP address
aliasing (multihoming) to define a "floating IP address" associated with
multiple application servers or hosts. When one application server in a cluster
fails, another cluster node can assume the responsibilities of the application
server without requiring the user to reconfigure the clients.
To support address aliasing, application groups contain an IP address resource and a recovery domain. When the application or the node running the application fails, Cluster Resource Services initiates a failover of the group using the IP address to the node assigned the current role of first backup.
The address specified for the takeover IP address must not be used for any other purposes. Cluster Resource Services will not allow certain API operations to complete successfully if the IP address is in use. This restriction ensures that the structures being created will provide application resilience.
A server takeover IP address is just like the
application
takeover IP address for an
application CRG, except it is used for servers associated with the relational
database name in the device description for an auxiliary storage pool. The
address can only be specified for a primary auxiliary storage pool. Only one IP
address can be specified per primary auxiliary storage pool. The address must
be unique, and must not be used for any other purpose.
The user is responsible for configuring and managing the server takeover IP address. The IP address must be added on all nodes in the recovery domain prior to starting the cluster resource group. Starting of a device cluster resource group will not start the server IP address or vary on the device. That is the user's responsibility. Cluster Resource Service manages the IP address only during a switchover or failover.
On switchover or failover, clustering will end the IP address on the current primary, and uses the value in the "configuration object online" field to determine what action should occur on the new primary node. Based on the value in the "configuration object online" field it will either start the IP address and vary on the device or do nothing to the IP address and device.
A failover message queue allows a user to control what happens at failover time. A failover policy could be:
A failover message queue may be specifed when a cluster resource group is created. A message will be placed on the queue when the primary node of the active cluster resource group either ends or fails, forcing the cluster resource group to fail over to a new primary. In the case of a node failure, each cluster resource group will enqueue a separate message to its failover message queue if one is defined. No message will be enqueued if the primary node is removed from the cluster.
The message will be placed on the message queue on the new primary node before the call to the exit program. This gives the user the option of continuing the failover to the new primary, or cancelling the failover. If the failover is cancelled, the primary node will not be changed, and the cluster resource group will become Inactive. The exit program will be called with an action code of Failover Cancelled.
There are two associated parameters with the qualified failover message queue. The failover wait time allows the user to specify how long Cluster Resource Services should wait for a reply to the failover message. The user can choose to wait forever, proceed with failover without waiting for a reply, or wait a specified number of minutes. The failover default action allows the user to choose whether to continue or cancel failover if a reply to the failover message is not received within the time limit specified in the failover wait time parameter or if the message cannot be enqueued for some reason.
Site name and data port IP addresses are associated with a recovery domain node for a device CRG, applicable only to cross-site mirroring. Both must be specified together for a recovery domain node. That is, a node which has a site name must also have at least one data port IP address specified.
Geographic mirroring, which is a subfunction of cross-site mirroring, supports two physical copies of auxiliary storage pool, one on each site. Only two sites are supported. A site primary node is the node which has the highest node role ranking for that site. A production site primary node, which is also the primary node for a device CRG, owns a production copy of the auxiliary storage pool. A mirror site primary node, which is the backup node which has the highest node role ranking at the mirror site, owns a mirror copy of the auxiliary storage pool.
A site may contain one or more recovery domain nodes at the same physical location. All nodes at a site must have access to the same physical copy of auxiliary storage pool. If there is only one node at a site, the auxiliary storage pool on that site does not need to be switchable. A node which belongs to more than one device CRG may or may not have the same site name.
Geographic mirroring is performed by sending updates from a production site primary node to a mirror site primary node via data port IP addresses. Each recovery domain node could have up to four data port IP addresses. They must be unique across all recovery domain nodes and CRGs.
User is responsible for configuring and managing data port IP addresses.
They must already exist on all nodes in the recovery domain prior to
starting a device CRG.
Clustering will not start or end data port IP addresses under any circumstances,
including starting and ending of a cluster resource group, switchover and failover.
User must start the data port IP addresses before geographic
mirroring can be performed. It is recommended that data port IP addresses are
dedicated for geographic mirroring use only.
It is also recommended that multiple data port IP addresses on each recovery domain node
map to different adapters. This will help to avoid a single point of failure on the
adapter and also improve performance of geographic mirroring.
Each cluster resource group has a status associated with it. The status of the cluster resource group may govern the behavior of a particular API call. In the following list of values, an indication of what happens when the exit program completes successfully applies only to a cluster resource group which has an exit program. If no exit program was specified, the same action occurs as for a successful completion. The possible values are:
10 Active. The resources managed by the cluster resource group are currently resilient.
20 Inactive. The resources managed by the cluster resource group are currently not resilient.
30 Indoubt. The information contained within the cluster resource group object may not be accurate. This status occurs when an exit program is called with an action of Undo and fails to complete successfully.
40 Restored. The cluster resource group object was restored on this node and has not been copied to the other nodes in the recovery domain. When Cluster Resource Services is started on this node, the cluster resource group will be synchronized with the other nodes in the recovery domain and its status set to Inactive.
500 Add Node Pending. A new node is in the process of being added to the recovery domain of a cluster resource group. If the exit program is successful the status is reset to its value at the time the API was called. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
510 Delete Pending. Cluster resource group object is in the process of being deleted. When the exit program completes the cluster resource group is deleted from all nodes in the recovery domain.
520 Change Pending. The cluster resource group is in the process of being changed. If the exit program is successful the status is reset to the value at the time the API was called. If the exit program fails and the original state cannot be recovered, status is set to Indoubt.
530 End Cluster Resource Group Pending. Resiliency for the cluster resource group is in the process of ending. If the exit program is successful, the status is set to Inactive. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
540 Initialize Pending. A cluster resource group is being created and is in the process of being initialized. If the exit program is successful, the status is set to Inactive. If the exit program fails, the cluster resource group will be deleted from all nodes.
550 Remove Node Pending. A node is in the process of being removed from the recovery domain of the cluster resource group. If the exit program is successful, the status is reset to the value at the time the API was called. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
560 Start Cluster Resource Group
Pending. Resiliency is in the process of starting for the
cluster resource group. If the exit program is successful, the status is set to
Active. If the exit program fails and the original state cannot be recovered,
the status is set to Indoubt. For
peer model cluster resource groups all nodes defined with a role of peer are active
access points for the cluster resources.
570 Switchover Pending. The Initiate
Switchover API was called, a failure of a cluster resource group occurred, or a
node failed, causing a switchover or failover to begin. The first backup node is
in the process of becoming the primary node. If the exit program is successful,
the status is set to Active. If the exit program fails and the original state
cannot be recovered, the status is set to Indoubt.
While the switchover function is not
valid for a peer cluster resource group, users may see the status "switchover
pending" during a node failure.
580 Delete Command Pending. Cluster resource group object is being deleted by the Delete Cluster Resource Group (DLTCRG) command. The Cluster resource group object is only removed from the node running the command. This is not a distributed request. At the completion of the command, the cluster resource group is deleted from the node.
590 Add Device Entry Pending. A device entry is being added to a cluster resource group. If the exit program is successful, the status is reset to its value at the time the API was called. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
600 Remove Device Entry Pending. A device entry is being removed from a cluster resource group. If the exit program is successful, the status is reset to its value at the time the API was called. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
610 Change Device Entry Pending. A device entry is being changed in a cluster resource group. If the exit program is successful, the status is reset to its value at the time the API was called. If the exit program fails and the original state cannot be recovered, the status is set to Indoubt.
620 Change Node Status Pending. The status of a node in the cluster resource group"s current recovery domain is being changed. If the change is successful, the status is reset to its value at the time the Change Cluster Node Entry API was called. Failure of the exit program causes the status of the cluster resource group to be set to Indoubt. If a backup node is reassigned as the primary node for a resilient device cluster resource group and the ownership of the device cannot be transferred to the new primary node, the status is set to Indoubt.
The relationship between the cluster resource group status and the cluster
resource group APIs is summarized in the following table. See the cluster
resource group APIs for additional details on the cluster resource group
status.
Summary of cluster resource group statuses for affected Cluster Resource Services API
| Cluster Resource Services API | Original status | Status while exit program running | Action Code | Status - exit program successful | Status - exit program failure on Undo |
|---|---|---|---|---|---|
| Add Cluster Resource Group Device Entry |
|
Add Device Entry Pending | 17 - Add Device Entry | original status | Indoubt |
| Add Node to Recovery Domain |
|
Add Node Pending | 11 - Add Node | original status | Indoubt |
| Change Cluster Node Entry | When changing node status:
|
Change Node Status Pending | 20 - Change Node Status | original status | Indoubt
** Indoubt if device ownership cannot be transferred for a resilient device cluster resource group. |
| Change Cluster Resource Group | If changing node to primary or changing takeover
IP address:
All other changes:
|
Change Pending | 13 - Change
Note: Only call exit program for changing node role in recovery domain. |
original status | Indoubt |
| Change Cluster Resource Group Device Entry |
|
Change Device Entry Pending | 19 - Change Device Entry | original status | Indoubt |
| Create Cluster Resource Group | N/A | Initialize Pending | 1 - Initialize | Inactive | *CRG deleted |
| Delete Cluster Resource Group |
|
Delete Pending |
|
*CRG deleted |
** Indoubt if Cluster Resource Services fails |
| End Cluster Resource Group |
|
End Cluster Resource Group Pending | 4 - End | Inactive | Indoubt |
| End Cluster Node |
|
Switchover Pending |
|
original status | Indoubt |
| Initiate Switchover |
|
Switchover Pending | 10 - Switchover
Note: If application cluster resource group, exit program called again with action Start. |
Active | Indoubt |
| Remove Cluster Node Entry |
|
Switchover Pending |
|
original status | Indoubt |
| Remove Cluster Resource Group Device Entry |
|
Remove Device Entry Pending | 18 - Remove Device Entry | original status | Indoubt |
| Remove Node From Recovery
Domain |
|
Remove Node Pending | 12 - Remove Node | original status | Indoubt |
| Start Cluster Node Entry |
|
No pending value used |
8 - Rejoin | original status | Indoubt |
| Start Cluster Resource Group |
|
Start Cluster Resource Group Pending | 2 - Start | Active | Indoubt |
For primary-backup model cluster
resource groups:
The primary partition contains the node that has the current node role of primary. All other partitions are secondary. The primary partition may not be the same for all cluster resource groups.
For peer model cluster resource
groups:
The restrictions for each API when in a partition state are:
Allowed in all partitions for peer cluster resource groups, but only affects the partition running the API.Allowed in all partitions for peer cluster resource groups, but only affects the partition running the API.By applying these restrictions, cluster resource groups can be
resynchronized when the cluster is no longer partitioned. As nodes rejoin the
cluster from a partitioned status, the version of the
cluster resource group in the primary partition will be copied to nodes in a secondary
partition.When merging two secondary
partitions for peer-model, the partition which has cluster resource group with status
of Active will override the other partition. If both partitions have the same status for
cluster resource group, the partition which contains the first active node listed in
the cluster
resource group recovery domain will be copied to all nodes in the recovery domain.
The version of the
cluster resource group in the winning partition will be copied to nodes in
the overridden partition.
On occasion, a partition condition may be reported incorrectly and one or more nodes may have actually failed. If one of these failed nodes has the current role of primary for a cluster resource group, special recovery actions are required in order to assign the primary node role to a node in a secondary partition.
After these actions have been taken, returning the failed nodes to the cluster becomes much more difficult. Thus, these actions should be taken only when the failed node will be unavailable for an extended period of time. An example of when to do this would be the loss of a primary site.
The Change Cluster Node Entry API may be used to tell Cluster Resource Services that a node has really failed rather than partitioned. Once all nodes have been identified as failing, the List Cluster Resource Group Information API can be used to determine if the recovery domain has been reordered as the situation requires, and the Start Cluster Resource Group API can be used to restart the cluster resource group.
See Change Cluster Node Entry
(QcstChangeClusterNodeEntry) API for additional information.
The cluster resource group APIs are:
| Top | Cluster APIs | APIs by category |