For more advanced functions of the Open Query File (OPNQRYF) command (such as dynamically joining records from different files), you must define a new file that contains a different record format.
This new file is separate from the one you are going to process and contains the fields that you want to create with the OPNQRYF command. This powerful capability also lets you define fields that do not currently exist in your database records, but can be derived from them.
When you code your high-level language program, specify the name of the file with the different format so the externally described field definitions of both existing and derived fields can be processed by the program.
Before calling your high-level language program, you must specify an Override with Database File (OVRDBF) command to direct your program file name to the open query file. On the OPNQRYF command, specify both the database file and the new file with the special format to be used by your high-level language program. If the file you are querying does not have SHARE(*YES) specified, you must specify SHARE(*YES) on the OVRDBF command.
The following chart shows the process flow:
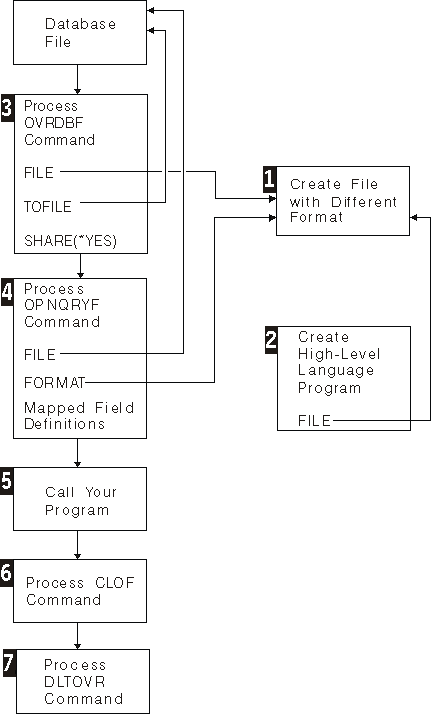
- 1
- Specify the data description specifications (DDS) for the file with the different record format, and create the file. This file contains the fields that you want to process with your high-level language program. Normally, data is not contained in this file, and it does not require a member. You normally create this file as a physical file without keys. A field reference file can be used to describe the fields. The record format name can be different from the record format name in the database file that is specified. You can use any database or DDM file for this function. The file can be a logical file and it can be indexed. It can have one or more members, with or without data.
- 2
- Create the high-level language program to process the file with the record format that you created in step 1. In this program, do not name the database file that contains the data.
- 3
- Run the OVRDBF command. Specify the name of the file with the different (new) record format on the FILE parameter. Specify the name of the database file that you want to query on the TOFILE parameter. You can also specify a member name on the MBR parameter. If the database member you are querying does not have SHARE(*YES) specified, you must also specify SHARE(*YES) on the OVRDBF command.
- 4
- Run the OPNQRYF command. Specify the database file to be queried on the FILE parameter, and specify the name of the file with the different (new) format that was created in step 1 on the FORMAT parameter. Mapped field definitions can be required on the OPNQRYF command to describe how to map the data from the database file into the format that was created in step 1. You can also specify selection options, sequencing options, and the scope of influence for the opened file.
- 5
- Call the high-level language program you created in step 2.
- 6
- The first file named in step 4 for the FILE parameter was opened with OPNQRYF as SHARE(*YES) and is still open. The file must be closed. The Close File (CLOF) command can be used.
- 7
- Delete the override that was specified in step 3.
The previous steps show the normal flow using externally described data. It is not necessary to create unique DDS and record formats for each OPNQRYF command. You can reuse an existing record format. However, all fields in the record format must be actual fields in the real database file or defined by mapped field definitions. If you use program-described data, you can create the program at any time.
You can use the file created in step 1 to hold the data created by the OPNQRYF command. For example, you can replace step 5 with a high-level language processing program that copies data to the file with the different format, or you can use the Copy from Query File (CPYFRMQRYF) command. The Copy File (CPYF) command cannot be used. You can then follow step 5 with the CPYF command or Query.