Problems with data integrity develop because users are operating with CCSIDs that have varied character support. That is, not all characters in CCSID 37 are available in CCSID 875 and vice versa.
Assume that the following names are to be entered by the English-speaking user (display device supports a CCSID of 37):
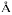 alson
alson- Gifford
When these entries are stored, the data integrity remains intact. That
is, an is
stored as an .
This is because the display device CCSID and the database CCSID are both 37.
Assume the following names are also input into DATABASE1 by the Greek-speaking user (display device CCSID of 875):
DATABASE1 now consists of the following logical entries:
- alson
- Gifford
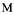
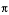
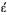
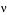
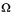

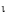


The Greek characters that make up the name are stored as those characters
only if the same character exists within CCSID 37. If the character does not
exist, the server converts the characters using a predetermined algorithm
to a code point from code page 37. The algorithm converts to .
The following list shows the code point used to store the first character of each name in DATABASE1. (Using only the first character makes the example easier by eliminating long strings of code points which are shown if the code point is presented for each character in the name.)
- Name
- CCSID 37 Stored Code Point (Hexadecimal)
- alson
- 67 . . .
- Gifford
- C7 . . .
-
- 53 . . .
-
- 67 . . .
The next step in this example is to show how data can be incorrectly selected due to the character conversion when it was stored in the database.
Assume that the Greek user wants to find all names beginning
with . The
following SQL statement can provide two names: and alson
Select from DATABASE1 where name LIKE ' %'
The search yielded an unexpected name ( alson). This is because the first character in alson is stored with
the same code point as the first character in .