Unicode is a standard that precisely defines a character set as well as a small number of encodings for it. It enables you to handle text in any language efficiently. It allows a single application to work for a global audience.
Before Unicode, the encoding systems that existed did not cover all the necessary numbers, characters, and symbols in use. Different encoding systems might assign the same number to different characters. If you used the wrong encoding system, your output might not have been what you expected to see.
Unicode provides a unique number for every character, regardless of platform, language, or program. Using Unicode, you can develop a software product that works with various platforms, languages, and countries. Unicode also allows data to be transported through many different systems. Modern systems provide Internationalization solutions based on Unicode.
Unicode was developed as a single-coded character set that contains support for all languages in the world. The first version of Unicode used 16-bit numbers, which allowed for encoding 65 536 characters without complicated multibyte schemes. With the inclusion of more characters, and following implementation needs of many different platforms, Unicode was extended to allow more than one million characters. Several other encoding schemes were added. This introduced more complexity into the Unicode standard, but far less than managing a large number of different encodings.
Starting with Unicode 2.0 (published in 1996), the Unicode standard began assigning numbers from 0 to 1 114 111. This gives more than enough room for all written languages in the world. The original repertoire covered all major languages commonly used in computing. Unicode continues to grow, and it includes more scripts.
The design of Unicode differs in several ways from traditional character sets and encoding schemes:
- Its repertoire enables users to include text efficiently in almost all languages within a single document.
- It can be encoded in a byte-based way with one or more bytes per character, but the default encoding scheme uses 16-bit units that allow much simpler processing for all common characters.
- Many characters, such as letters with accents and umlauts, can be combined
from the base character and accent or umlaut modifiers. This combining reduces
the number of different characters that need to be encoded separately. Precomposed variants
for characters that existed in common character sets at the time were included
for compatibility. For example, Latin small letter A used with a combining
tilde results in
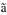 .
.
Characters and their usage are well-defined and described. Traditional character sets typically provide only the name or a picture of a character and its number and byte encoding; Unicode has a comprehensive database of properties available. It also defines a number of processes and algorithms for dealing with many aspects of text processing to make it more interoperable.
The early inclusion of all characters of commonly used character sets makes Unicode a useful mechanism for converting between traditional character sets, and makes it feasible to process non-Unicode text by first converting the text into Unicode, processing the text, and then converting it back to the original encoding without loss of data.